# Het internet
# Geschiedenis
Er doen heel wat verhalen de ronde over de geschiedenis van het Internet. Eén van de grote misverstanden is dat het Internet zou ontstaan zijn in de jaren zestig als een project van het Ministerie van Defensie van de Verenigde Staten, dit klopt dus niet maar de basis van het World Wide Web lag wel degelijk in Amerika.
De bedoeling was een gedecentraliseerd netwerk te creëren dat nog steeds zou werken als bepaalde delen plat zouden liggen. Dus in plaats van lineair geschakelde computers waarbij het hele netwerk ontregeld is als één schakel ontbreekt, werden de computers als in een web met elkaar verbonden.
Internet zou gebouwd zijn als een super-redundant netwerk dat zelfs een kernaanval moest kunnen doorstaan. De oorsprong van internet dateert weliswaar van de periode van de koude oorlog tussen Amerika en Rusland. In 1957 gaat er een schok door Amerika als Rusland zijn technologisch leiderschap in de ruimte vestigt door de Sputnik I en Sputnik II binnen een maand na elkaar te lanceren. In die tijd waren de computers van het Amerikaans leger verbonden door één lijn: computer A was verbonden met computer B, computer B met C enz. Computer A kon wel communiceren met computer Z, maar had daarvoor computer B, C,D… nodig. Een ketting waarin elke computer de zwakke schakel was. Een militaire ramp wanneer een Russische kernbom computer K zou platleggen, want dan konden A en Z niet meer met elkaar overleggen.
De president van Amerika, Eisenhower, neemt, mede in reactie daarop, het initiatief een R&D bureau (agency) te vestigen: Advanced Research Projects Agency. Enkele universiteiten in Californië dokterden een ingenieus systeem uit. Verbindt alles computer van A tot Z met elkaar. Wanneer computer A informatie naar computer Z wil versturen, dan bepaalt de software zelf wel welke weg het daarvoor wil nemen, bijvoorbeeld van A naar X, van X naar D, van D naar T, om ten slotte van T bij Z te belanden. Werd één schakel onschadelijk gemaakt, dan werd automatisch een andere weg genomen om de informatie door te sturen.
Informatie werd ook in pakketjes verstuurd. Computer A verstuurde een pakketje informatie naar computer D. Was het pakketje goed aangekomen, dan vertelde D dit aan A die een nieuw pakketje verzond, eventueel via een andere computer. Alle pakketjes kregen een nummer en een adres, zodat op het einde van de ketting alle pakketjes bij de juiste computer terecht kwamen en in de goede volgorde.
Tien jaar later, in 1968, stuurt Larry Roberts, werkzaam bij ARPA, een verzoek om offertes naar 140 firma’s, om een IMP te maken. Een IMP, Interface Message Processor, moest een aparte computer zijn, die met andere IMP’s via packet switching kon communiceren.
Het ARPAnet, de voorganger van het internet, was geboren. In 1972 waren er al 37 netwerken op het systeem aangesloten. Niet alleen de militaire wereld zag de grote voordelen in van zo’n groot netwerk. Universiteiten van over de hele wereld werden met elkaar verbonden.
Daartoe ontwikkelden ze een eigen netwerk, TCP/IP zag het daglicht -een verbetering van de “pakketpost” en is nog steeds het hart van ons huidige internet. Enkele studenten aan de universiteiten van California ontwikkelden nieuwe toepassingen voor dit netwerk: elektronische post (email), verzenden en ontvangen van software, nieuwsgroepen. De uitvinding van het netwerk waarvan internet gebruik maakt is dus een Amerikaanse uitvinding.
Maar het World Wide Web is een zuiver Europese uitvinding waarin zelfs de Belg Robert Cailliau (opens new window) een hoofdrol gespeeld heeft.Dit ontwikkelde hij samen met Tim Berners-Lee (opens new window).
De eerste website werd gemaakt in 1991, deze kan je hier bezoeken: http://info.cern.ch/hypertext/WWW/TheProject.html (opens new window)
In de beginjaren was het gezicht van internet helemaal niet dat wat we nu gewoon zijn. Websites bestonden er niet. Alle informatie werd op een droge manier aan de man gebracht. Daar kwam verandering in toen aan de CERN in Zwitserland eind de jarig tachtig het WWW werd ontwikkeld, gebaseerd op sites die door middel van links met elkaar waren verbonden. De grondslag was gelegd om internet populair te maken. Daarom kreeg eind de jaren ’80 de commerciële wereld belangstelling voor internet en toen zat het spel pas goed op de wagen.
# Evolutie van het web
Om te begrijpen hoe Content Management Systems (CMS) voor het eerst op het toneel verschenen en waarom er verschillende typen zijn, blikken we terug op hoe inhoud zich op internet heeft ontwikkeld.
# Web 1.0, het beheren van statische web content
Web 1.0 is de term die wordt gebruikt om te verwijzen naar de eerste ontwikkelingsfase op het World Wide Web die werd gekenmerkt door eenvoudige statische websites. De geschiedenis van contentmanagementsystemen begon in 1989 toen Tim Berners-Lee een internetgebaseerd hypertextsysteem HTML voorstelde en eind 1990 de browser- en serversoftware schreef. HTML kwam van SGML, wat staat voor de Standard Generalized Markup Language, en werd gemaakt bij IBM door Charles F. Goldfarb, Ed Mosher en Ray Lorie in de jaren zeventig. De eerste websites waren eenvoudige HTML-tekstbestanden. Er werd gebruik gemaakt van een FTP-programma om de bestanden naar een map onder een actieve webserver te kopiëren.

In 1993 begonnen Mosaic-browsers afbeeldingen te ondersteunen die konden verschijnen naast tekst, en statische brochure-achtige sites deelden bedrijfs- en productinformatie.

In de vroege jaren 1990 kwam de eerste stap naar het beheren van inhoud op een webpagina met Server Side Includes (SSI). Met Server Side Includes kunt u delen van uw site gescheiden houden van de hoofdinhoud, zoals het sitemenu of een voettekst. Rond dezelfde tijd verscheen de Common Gateway Interface waarmee je interactieve formulieren kon maken.
 Al in 1990 zei Tim Berners-Lee dat het scheiden van de documentstructuur van de lay-out van het document een doel van HTML was geweest. In 1994 werkte Håkon Wium Lie bij CERN en het gebruik van internet voor publicaties groeide. Het was echter niet mogelijk om documenten te stijlen, zoals het weergeven van een lay-out met meerdere kolommen in krantenstijl op een webpagina. Lee zag de noodzaak in van een stylesheet-taal voor het web. Later werd Lie vergezeld door Bert Bos, die een aanpasbare browser met stylesheets bouwde. Tegen 1995 was het World Wide Web Consortium (W3C) operationeel en Lie en Bos werkten bij het W3C samen aan de aanbevelingen voor de eerste stylesheets.
Al in 1990 zei Tim Berners-Lee dat het scheiden van de documentstructuur van de lay-out van het document een doel van HTML was geweest. In 1994 werkte Håkon Wium Lie bij CERN en het gebruik van internet voor publicaties groeide. Het was echter niet mogelijk om documenten te stijlen, zoals het weergeven van een lay-out met meerdere kolommen in krantenstijl op een webpagina. Lee zag de noodzaak in van een stylesheet-taal voor het web. Later werd Lie vergezeld door Bert Bos, die een aanpasbare browser met stylesheets bouwde. Tegen 1995 was het World Wide Web Consortium (W3C) operationeel en Lie en Bos werkten bij het W3C samen aan de aanbevelingen voor de eerste stylesheets.
In augustus 1996 was de eerste commerciële browser die CSS ondersteunde Internet Explorer 3 van Microsoft. De volgende browser die CSS ondersteunde was Netscape Communicator, versie 4.0. De eerste implementatie van Netscape ter ondersteuning van CSS was meer een poging om Microsoft ervan te weerhouden te beweren dat het meer aan de normen voldoet dan Netscape. Helaas crashte de Netscape-browser vaak wanneer de pagina Cascading Style Sheets bevatte. De strijd om het beheersen van standaarden tussen Netscape en Microsoft werd bekend als de browseroorlogen.
 In 1996 voegde ColdFusion een volledige scripttaal toe met de naam CFML. Formulieren verwerken met ColdFusion of met behulp van de Common Gateway Interface en programmeertalen zoals Perl en Python werden de norm. Van 1995 tot 1997 was scripting op de server een rage. In dezelfde periode speelden Personal HomePage (PHP) en Active ServerPages (ASP) een rol met scripting op de server voor het genereren van inhoud die van de server naar de webbrowser werd verzonden. Net als ASP en PHP, kwamen JavaServer Pages (JSP) later in 1999 op het toneel en werd gebouwd rond de programmeertaal Java en was ook redelijk populair.
In 1996 voegde ColdFusion een volledige scripttaal toe met de naam CFML. Formulieren verwerken met ColdFusion of met behulp van de Common Gateway Interface en programmeertalen zoals Perl en Python werden de norm. Van 1995 tot 1997 was scripting op de server een rage. In dezelfde periode speelden Personal HomePage (PHP) en Active ServerPages (ASP) een rol met scripting op de server voor het genereren van inhoud die van de server naar de webbrowser werd verzonden. Net als ASP en PHP, kwamen JavaServer Pages (JSP) later in 1999 op het toneel en werd gebouwd rond de programmeertaal Java en was ook redelijk populair.
In 1997 introduceerde Microsoft iFrames waarmee je het HTML-browservenster in segmenten kunt splitsen, waarbij elk frame een ander document toont dat kan worden gebruikt om inhoud van andere sites weer te geven en populair was voor het presenteren van advertenties en banners. De iframe-tag bracht echter beveiligings-, navigatie- en seo-problemen met zich mee die uiteindelijk werden aangepakt.
# De DOM en dynamische HTML-revolutie
Het keerpunt kwam in 1997 toen dynamische content tot zijn recht kwam met de introductie van het Document Object Model (DOM). De DOM definieert de logische structuur van documenten waarmee u delen van een document kunt identificeren en programmeren. De DOM is een applicatie-programmeerinterface (API) voor HTML- en XML-documenten. Met de DOM kunt u bijvoorbeeld de stijlen van HTML-elementen openen en manipuleren, zoals de hele body (body) of een divisie (div) op een pagina.
Dynamische HTML met behulp van asynchrone JavaScript en XML, gewoonlijk Ajax genoemd, was een revolutionaire doorbraak waardoor ontwikkelaars gegevens konden opvragen en ontvangen om een webpagina bij te werken zonder de pagina opnieuw te laden.
# Web 2.0 en de noodzaak naar een CMS
Dynamische inhoudslevering bracht nieuwe manieren om inhoud op het web te presenteren en te gebruiken, met de nadruk op sites die socialer zijn. Web 2.0 verwijst naar de toename van door gebruikers gegenereerde inhoud en het gebruiksgemak om websites met andere producten en systemen te laten werken.
Terwijl het internet veranderde van statische sites naar steeds interactievere sites met dynamische inhoud, groeide de wens naar samenwerking en nieuwe, relevante inhoud en kwam de behoefte om inhoud te beheren naar voren. Websites moesten dagelijks worden bijgewerkt, waarbij verschillende mensen inhoud wilden toevoegen en bewerken.
De marketingafdeling wil bijvoorbeeld promotiemateriaal bijwerken, Human Resources moet nieuwe vacatures plaatsen, de Public Relations-afdeling moet persberichten posten, de Documenten-afdeling moet productdocumentatie publiceren, de ondersteuningsafdeling wil online communiceren met klanten en spoedig.
De rol van een contentmanagementsysteem was om meerdere gebruikers met verschillende machtigingsniveaus de mogelijkheid te bieden content voor een website of een gedeelte van de content te beheren.
Eind jaren negentig en begin 2000 gaven mobiele apparaten van Nokia Symbian, Palm en Blackberry toegang tot het web. Pas bij de introductie van de iPhone in 2007 en de Android-smartphone in 2008 hadden mobiele telefoons echt invloed op de levering van webcontent. In 2010 verschenen slimme tablets. REST API’s en JSON-gegevensindeling waren essentieel voor het leveren van inhoud aan mobiele apparaten. Deze megatrend van het leveren van inhoud aan mobiele apparaten luidde het mobiele webtijdperk in. Begin 2014 overtrof het gebruik van mobiel internet het desktopgebruik in de VS.
Deze toename van het inhoudsverbruik door mobiele apparaten vormde een probleem voor het monolithische CMS dat expliciet werd gemaakt voor het leveren van webinhoud aan desktops en laptops. Er was geen manier om op betrouwbare wijze inhoud te leveren voor zowel desktop- als mobiele apparaten. Om de opkomst van mobiel internetgebruik aan te pakken, begonnen ontwikkelaars zowel desktop- als mobiele versies van hun websites te maken, met mobiele ontwerpen die uitgeklede versies van geselecteerde desktopwebsite-pagina’s aanbieden.
De mobiele sites bevonden zich op een afzonderlijk subdomein en werden mobiele sites of ‘m.dot’-sites genoemd, omdat de subdomeinen zouden eindigen op’ .m '. Een probleem dat zich voordeed, is dat Google geen indexering van m.dot-sites biedt. In plaats daarvan annoteert Google alleen de m.dot-URL’s om te zeggen dat de hoofdwebsite mobielvriendelijk is.
In 2010 introduceerde Ethan Marcotte de term ‘responsive design’ die een verschuiving in het denken bevorderde van het vaste ontwerp voor desktopwebsites naar responsieve, vloeiende, aanpasbare lay-outs. Om de belofte van responsief ontwerp waar te maken, heeft de W3C mediaquery’s gemaakt als onderdeel van de CSS3-specificatie. Met een mediaquery kunnen ontwikkelaars het type apparaat vaststellen en de fysieke kenmerken van het apparaat controleren, zoals de schermgrootte. Met CSS kunt u bijvoorbeeld de regel @media gebruiken om te bepalen welke schermgrootte wordt gebruikt en een blok CSS-eigenschappen voor dat apparaat opnemen.
 De wereldwijde groei van mobiel gebruik (bron: StatCounter Global Stats
De wereldwijde groei van mobiel gebruik (bron: StatCounter Global Stats
# Web API’s, XML en JSON
Een groot deel van Web 2.0 was het laten werken van websites met andere producten en systemen. Een web-API is een programmeerinterface die toegang tot een systeem mogelijk maakt, zoals een website via standaard HTTP-aanvraagmethoden. De gegevens zijn meestal verpakt in een standaardindeling, zoals XML of JSON, zodat ze gemakkelijk te lezen en mee te werken zijn.
XML staat voor eXtensible Markup Language, een gegevensindeling. Net als HTML is XML een afstammeling van SGML, de Standard Generalized Markup Language. XML maakt het mogelijk gegevens te transporteren via feeds en API-aanroepen omdat het een platformonafhankelijk formaat is.
JSON staat voor JavaScript Object Notation, een indeling voor het opslaan van geserialiseerde gegevens met sleutel / waarde-paren en het verzenden van die gegevens tussen een server en een webtoepassing. JSON-feeds kunnen veel eenvoudiger asynchroon worden geladen dan XML- en RSS-feeds. Sommige sites, zoals Twitter, bieden RSS-feeds, die eenvoudig te gebruiken zijn aan de serverzijde maar frustrerend aan de clientzijde, omdat u een RSS-feed niet kunt laden met AJAX tenzij u deze aanvraagt vanuit hetzelfde domein waarop deze zich bevindt gehost. JSON verkreeg ook de voorkeur boven XML, omdat het een kleinere voetafdruk heeft, gemakkelijker te gebruiken is en goed werkt met JavaScript-compatibele browsers, omdat JavaScript automatisch JSON herkent.
bron: https://www.contentstack.com (opens new window)
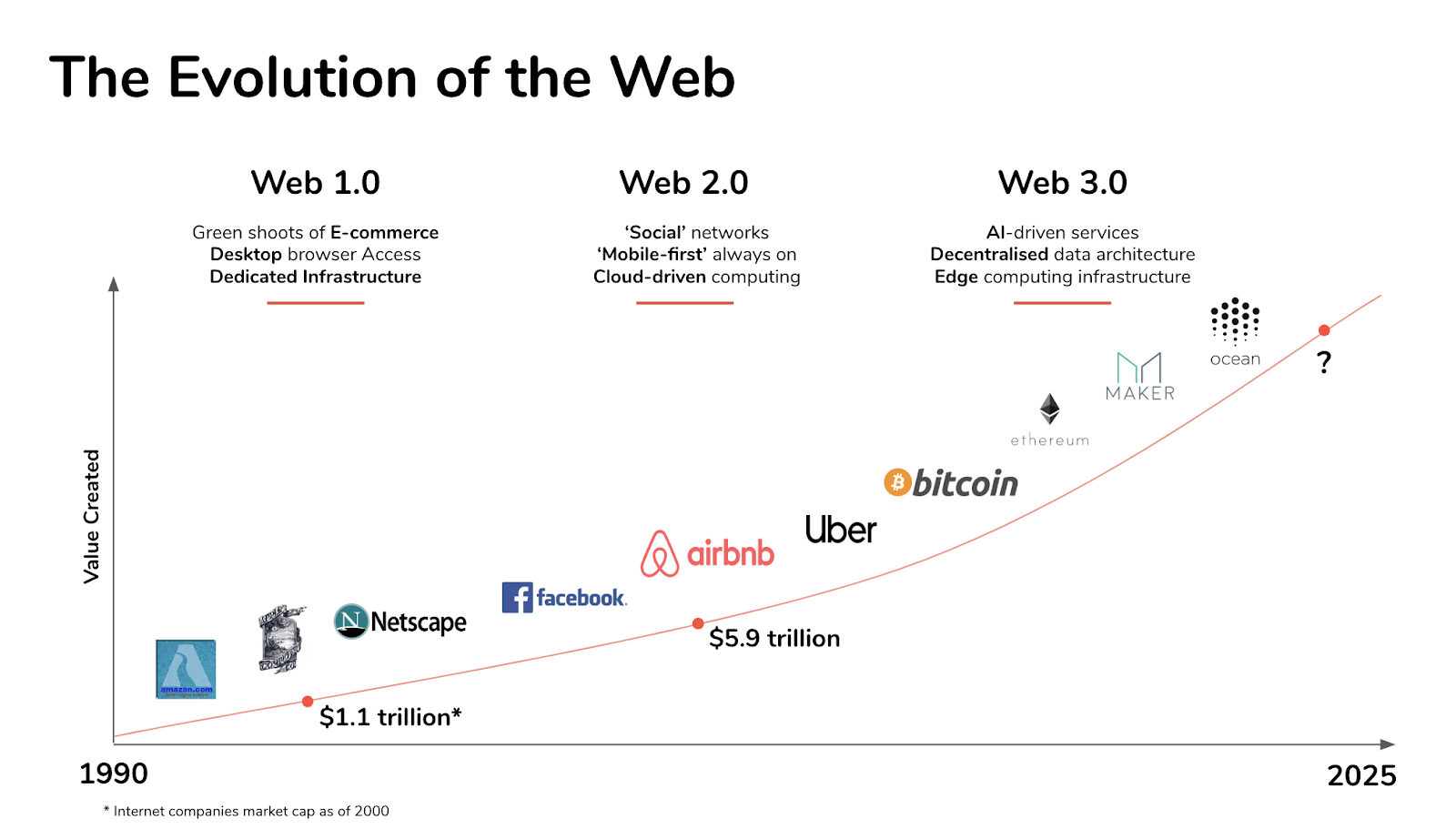
# Web 3.0
Web 2.0 was vooral gedreven door de integratie van verschillende platformen, mobiele applicaties, sociale netwerken etc. Ook al is de start van deze evolutie al even geleden, we dragen dit nog heel erg mee in de huidige staat van het web.
Web 3.0 is de nieuwe evolutie die momenteel nog volop bezig is, om het in 1 woord samen te vatten staat Web 3.0 voor decentralisatie. Het is het nastreven naar open, gedecentraliseerde netwerken zonder overkoepelende partij.
Ook de opkomst van Artificiële Intelligentie en Machine Learning horen bij deze evolutie.
# Organisatie van het internet
Wil men aansluiten op het internet dan moet men een verbinding hebben met een ander knooppunt dat aan het internet hangt. Een Internetaanbieder (in het engels Internet Access Provider) is een commerciële firma die Internetdiensten aanbiedt. In ons land zijn meerdere Internetaanbieders actief, zij bieden een waaier van diensten aan, gaande van eenvoudige diensten voor privé-gebruikers tot uitgebreide dienstenpakketten voor bedrijven. De meeste Internetaanbieders vragen een maandelijkse abonnementsprijs waarin een bepaald aantal uren Internetverbinding begrepen is. Boven dit plafond betaalt men een tarief per tijdseenheid.
Om een verbinding te leggen met een Internetaanbieder gebruikt men als privé-gebruiker een modem. Verder moet men over communicatie software beschikken die TCP/IP ondersteunt, en over toepassingssoftware. Van de Internetaanbieder krijgt men een IP-adres en een e-mail-adres om elektronische berichten te kunnen sturen en ontvangen. Bedrijven geven vaak de voorkeur aan een vaste verbinding, waarbij een vaste lijn gehuurd wordt van een telecom operator.
Belnet is een dienst van de Belgische overheid die in het leven geroepen werd om de communicatienoden van de onderzoeksinstellingen in België te ondersteunen. Momenteel biedt Belnet ook Internetdiensten aan alle openbare instellingen.
# Toepassingen van het internet
# World Wide Web
In grote lijnen werkt het WWW als volgt:
- Je typt het adres van een website in je webbrowser in. Zo’n adres heet officieel een URL, dat is een afkorting voor het engelse begrip Uniform Resource Locator.
- De webbrowser zoekt het IP-adres van deze website op (DNS)
- De browser stuurt een verzoek naar de webserver om een pagina te bekijken/downloaden
- De webserver zendt de gevraagde pagina terug naar je webbrowser
- De webbrowser toont de pagina op je scherm
Alle computers op het internet hebben een eigen uniek nummer, het zogenaamde IP-adres. Omdat het niet handig is om zo’n nummer te onthouden kan de eigenaar van de computer een domein naam aanvragen en deze aan het nummer laten koppelen.
De webbrowser moet het adres van de website die je hebt ingevoerd nu dus gaan omzetten in het IP-adres van de website. Daarom gaat de web browser contact maken met de DNS-server van je internet aanbieder. DNS is een afkorting voor het engelse begrip Domain Name System. Als dit contact tot stand is gebracht vraagt de webbrowser de DNS-server om het IP-adres dat hoort bij het adres van de website. Als het adres bestaat, krijgt de webbrowser vrijwel onmiddellijk antwoord, in de vorm van het gevraagde IP-adres. In dit verzoek staat uiteraard ook het IP-adres van je eigen computer, anders kan de website het antwoord niet naar de juiste plaats terugsturen.
IP-adres wordt voorgesteld door vier groepen getallen, gescheiden door een punt, zoals bijvoorbeeld 134.58.39.97.
De DNS-namen worden omgezet in IP-adressen door DNS-servers.
Het toekennen van DNS-namen gebeurt door erkende instellingen. In België gebeurt dit (momenteel nog) op het Departement Computerwetenschappen van de K.U.Leuven, omdat zij in België koplopers waren bij het gebruik van Internet.
Het IP-protocol bepaalt de regels voor het pakket-verkeer, het TCP-protocol verdeelt grotere hoeveelheden informatie in kleine pakketjes langs de kant van de verzender, en stelt de informatie weer samen aan de kant van de bestemmeling.
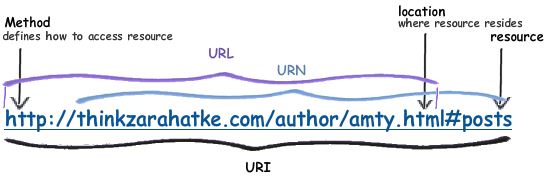
# URL
Een URL kan gebruikt worden om de locatie van bestanden op je computer weer te geven, of om de locatie van een database te tonen maar meestal zien we URL’s in de adresbalk van de browser.
Laten we deze twee URL’s ontleden als voorbeeld:
- https://www.google.be/search?q=wat+is+een+url
- http://blog.facebook.com/eerste-artikel?date=05.10.2021&author=adriaan#comments
# Protocol
- https
- http
https:// is het protocol in de bovenstaande URL. HTTPS staat voor “Hypertext Transfer Protocol Secure”. Het is de beveiligde variant van HTTP (Hypertext Transfer Protocol).
HTTPS wordt gebruikt voor een beveiligde communicatie tussen een browser en een server. De data is versleuteld, zodat alleen de verstuurder en de ontvanger het kunnen lezen. Hackers of andere kwaadwillenden kunnen er niet bijkomen.
De browser stuurt een verzoek aan de server om de bestanden te krijgen. De server verwerkt het verzoek en stuurt de bestanden. De bestanden worden uitgelezen in de browser en op deze manier ziet de bezoeker een website. Het HTTPS protocol maakt dit mogelijk op een veilige manier.
# Subdomein
- www
- blog
Subdomeinen fungeren als een extensie van je domeinnaam om te helpen bij het organiseren van en navigeren naar verschillende secties van je website. Je kunt ook een subdomein gebruiken om bezoekers naar een totaal ander webadres te leiden, zoals je sociale mediapagina, of om naar een specifiek IP-adres of een specifieke map binnen je account te wijzen.
# Domein (Top level domain)
De domeinnaam is het adres van een website. Het moet uniek zijn. Aan een domeinnaam is een IP-adres gekoppeld.
# Extensie
- be
- com
De extensie van een domeinnaam verwijst vaak naar de locatie van een website. Bij .com is dit niet het geval, het heeft een internationaal karakter.
# Poortnummer
- Niet zichtbaar
- Niet zichtbaar
In de bovenstaande URL’s staat geen poortnummer. Stel dat er wel een poortnummer in de URL zat, kon dat er zo uitzien: https://www.google.com:443
Het standaard poortnummer voor het HTTPS protocol is 443, daarom is het eigenlijk onnodig om dit poortnummer in de URL te zetten. Bij een niet-standaard poortnummer moet je het wel in de URL zetten.
Een IP-adres identificeert de bestemming van een computer en een poortnummer verwijst naar een applicatie/programma op de computer.
Poortnummer 443 zorgt er dus voor dat het verzoek van een browser terechtkomt bij een programma op de juiste computer. Dit programma handelt het verzoek netjes af, volgens de HTTPS standaarden.
Er zijn natuurlijk meerdere protocollen die allemaal hun eigen poortnummer hebben. Bijvoorbeeld HTTP heeft 80 als poortnummer en FTP (File Transfer Protocol) 21.
# Pad
- search
- eerste-artikel
Een pad verwijst naar een specifieke locatie op een server. Op deze locatie staan bestanden die het verzoek van een browser verder afhandelen en het juiste resultaat terugsturen.
# Query
- q=wat+is+een+url
- date=05.10.2021&author=adriaan
Een query wordt vaak gebruikt in een URL om een specifieke taak af te handelen, zodat de browser ook een specifiek resultaat terugkrijgt.
De server ontvangt het verzoek van de browser met de desbetreffende query. Op de server staan allemaal algoritmes die uitzoeken wat er moet teruggestuurd worden. De collectie van deze algoritmes heet een API.
# Anchor
- Niet aanwezig
- #comments
Een fragment/anchor is bedoeld om naar een bepaalde locatie/plek op een webpagina te gaan. Als je op de link klikt, ga je naar het volgende hoofdstuk.
Deze moet op het einde van de URL.
# HTTP Methodes
Zoals we reeds weten worden verzoeken naar de server gestuurd via het HTTP(s) protocol. Er zijn echter verschillende HTTP Methodes:
- GET
- POST
- PUT
- PATCH
- DELETE
# GET
The HTTP GET method is used to read (or retrieve) a representation of a resource. In case of success (or non-error), GET returns a representation in JSON and an HTTP response status code of 200 (OK). In an error case, it most often returns a 404 (NOT FOUND) or 400 (BAD REQUEST).
# POST
The POST method is most often utilized to create new resources. In particular, it is used to create subordinate resources. That is subordinate to some other (e.g. parent) resource. In other words, when creating a new resource, POST to the parent and the service takes care of associating the new resource with the parent, assigning an ID (new resource URI), etc.
On successful creation, HTTP response code 201 is returned.
# PUT
PUT is most-often utilized for update capabilities, PUT-ing to a known resource URI with the request body containing the newly-updated representation of the original resource.
However, PUT can also be used to create a resource in the case where the resource ID is chosen by the client instead of by the server. In other words, if the PUT is to a URI that contains the value of a non-existent resource ID. Again, the request body contains a resource representation. Many feel this is convoluted and confusing. Consequently, this method of creation should be used sparingly, if at all.
Alternatively, use POST to create new resources and provide the client-defined ID in the body representation—presumably to a URI that doesn’t include the ID of the resource (see POST below).
On successful update, return 200 (or 204 if not returning any content in the body) from a PUT. If using PUT for create, return HTTP status 201 on successful creation. A body in the response is optional—providing one consumes more bandwidth. It is not necessary to return a link via a Location header in the creation case since the client already set the resource ID.
PUT is not a safe operation, in that it modifies (or creates) state on the server, but it is idempotent. In other words, if you create or update a resource using PUT and then make that same call again, the resource is still there and still has the same state as it did with the first call.
If, for instance, calling PUT on a resource increments a counter within the resource, the call is no longer idempotent. Sometimes that happens and it may be enough to document that the call is not idempotent. However, it’s recommended to keep PUT requests idempotent. It is strongly recommended to use POST for non-idempotent requests.
# PATCH
PATCH is used to modify resources. The PATCH request only needs to contain the changes to the resource, not the complete resource.
In other words, the body should contain a set of instructions describing how a resource currently residing on the server should be modified to produce a new version.
# DELETE
DELETE is quite easy to understand. It is used to delete a resource identified by filters or ID.
On successful deletion, the HTTP response status code 204 (No Content) returns with no response body.
E-mail staat voor electronic mail, dus elektronische post. Het is een zeer veel gebruikte toepassing op het Internet. Je kan via e-mail niet minder dan 30 miljoen mensen bereiken. Als je daarbij bedenkt dat het vrijwel gratis is, enorm snel gaat, toelaat boodschappen te beantwoorden en verder te sturen naar anderen, kun je begrijpen dat dit een heel krachtig hulpmiddel is.
Met de elektronische post is het mogelijk een boodschap naar een correspondent te versturen, waar die zich ook ter wereld bevindt. Hij hoeft zelfs niet aangesloten te zijn op het ogenblik dat je de boodschap verstuurt. Het volstaat dat de bestemmeling over een elektronisch adres beschikt. Dit betekent dat er een computer is die aan het Internet hangt en die de post voor die gebruiker bijhoudt. Eens de boodschap is opgesteld wordt hij via het netwerk naar de computer van de correspondent verstuurd. Wanneer deze in zijn ‘brievenbus’ kijkt, vindt hij daar de boodschap. Post opvragen en doornemen kan op het moment dat het meest geschikt is voor de ontvanger.
Een e-mail boodschap bestaat uit twee delen: een briefhoofd (header in het Engels) en de eigenlijke boodschap. Het briefhoofd bevat verschillende administratieve gegevens (zender, ontvanger, onderwerp, …).
Er bestaan nogal wat e-mailprogramma’s met behulp waarvan elektronische post verstuurd en gelezen kan worden. Hoewel deze programma’s in een aantal opzichten van elkaar kunnen verschillen, bieden ze je basismogelijkheden die min of meer overal gelijk zijn:
- het lezen van binnengekomen berichten
- het opstellen en verzenden van berichten
- het beantwoorden van binnengekomen berichten
- het doorversturen van binnengekomen berichten
- het organiseren van de berichten die je ontvangt
- het bijhouden van e-mail adressen.
# FTP
FTP (File Transfer Protocol) is een protocol (reeks van regels en afspraken) om op een foutloze manier bestanden tussen computers te transporteren. Het werd reeds in 1971 geïntroduceerd en groeide uit tot een standaard. FTP is gemakkelijk om mee te werken.
Toegepast op Internet is FTP een manier om gegevens die zich ergens ter wereld in een ‘gast-’ of hostcomputer bevinden, op te vragen en naar je eigen computer over te hevelen of downloaden.
Voordat je een FTP-sessie kunt opstarten moet je eerst een connectie maken met de gastcomputer waarvan je bestanden wilt halen. Hiervoor moet je de DNS-naam van de gastcomputer opgeven. De gastcomputer zal je ook een identificatie en een wachtwoord vragen.